
Reducing 1.1 years of compute time — every single day
Cutting Lambda costs by $1M/year without changing infrastructure or traffic

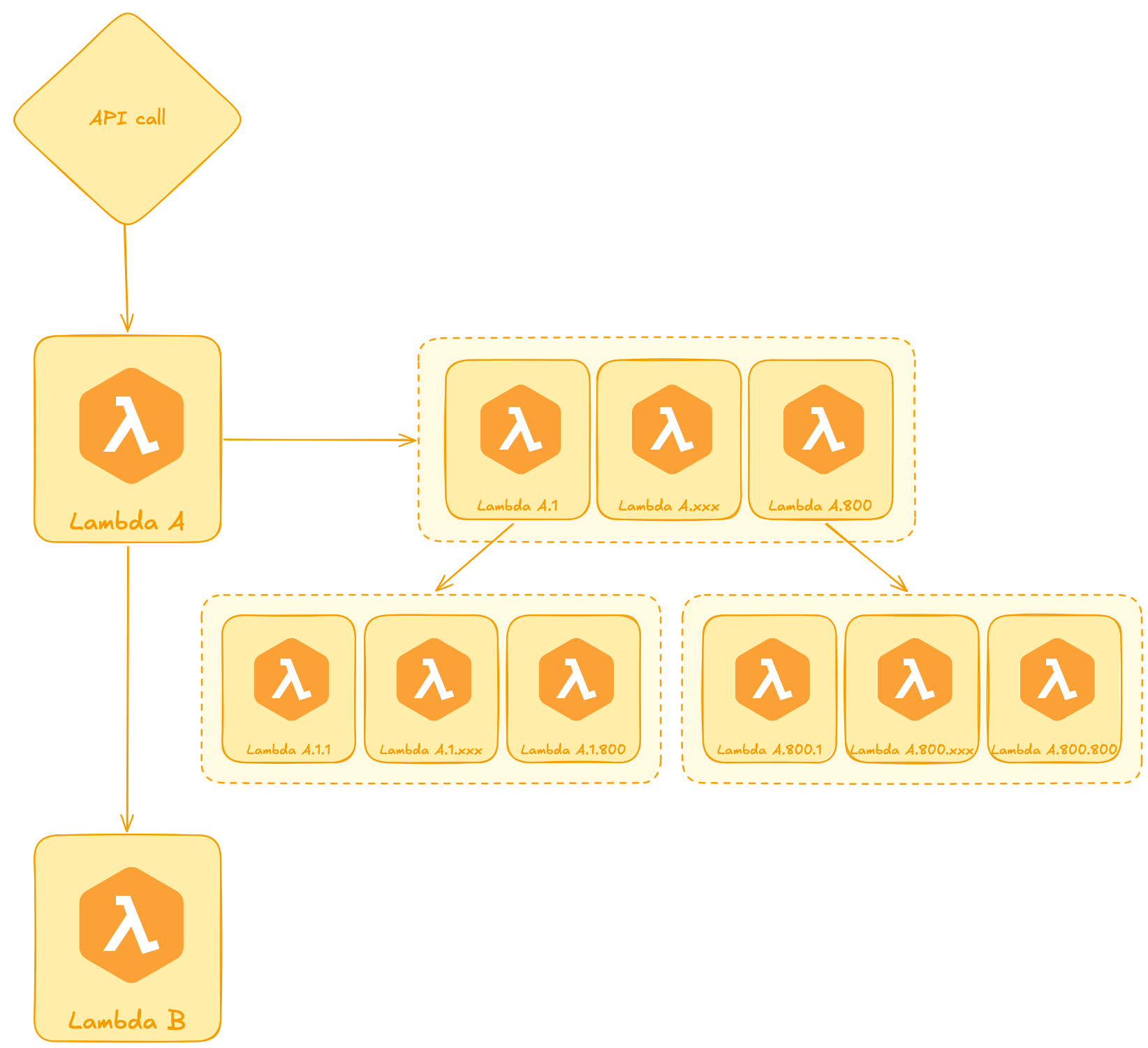
At first, leveraging a Lambda fan-out pattern for the sake of parallelisation does not seem inherently bad. But what happens when this pattern is blown out of proportion? What happens when a single Lambda call can spin up to 800 child Lambdas and those nested calls can do the same?
Imagine the architecture below - very quickly it becomes a time and money sink that scales up uncontrollably.
In this article we will be diving exactly into that pattern - and how at a scale of a million calls per day, optimising inefficiencies allowed us to save years of compute time daily, and close to $2 million/year across our development and production environments combined.
The system
The system being optimised was responsible for modelling network behaviour and comparing network state before and after changes to physical entities (such as network routers).
The results of the calculations were critical to assert that changing the physical network of millions of interlinked devices would not cause network impact such as bottlenecks, degradation or packet loss for AWS customers.
Moreover, due to how mission critical this system’s results were to operations, the faster an answer could be given, the better.
The scale
As previously mentioned, this system received about 1 million calls/day - with most of those calls being replicated automatically to the development environment for pre-release validation. So in total, about 2 million calls per day.
As for calculation times and SLAs… it depends. Ask any network engineer and they will tell you about the seemingly endless ways to connect a physical network and make them behave in their own funky little ways. Hence modelling a network of millions of physical devices, with different protocols, physical interfaces, lags, seemingly all shapes and sizes - and it becomes tough to have a uniform calculation across them all.
For simplicity sake, imagine this system either replied in 5-10 seconds, or it would take nearly all of its 180-second SLA to finish a calculation.
Performance bottlenecks in a distributed world
Our synchronous Lambda fan-out pattern introduced two immediate structural flaws:
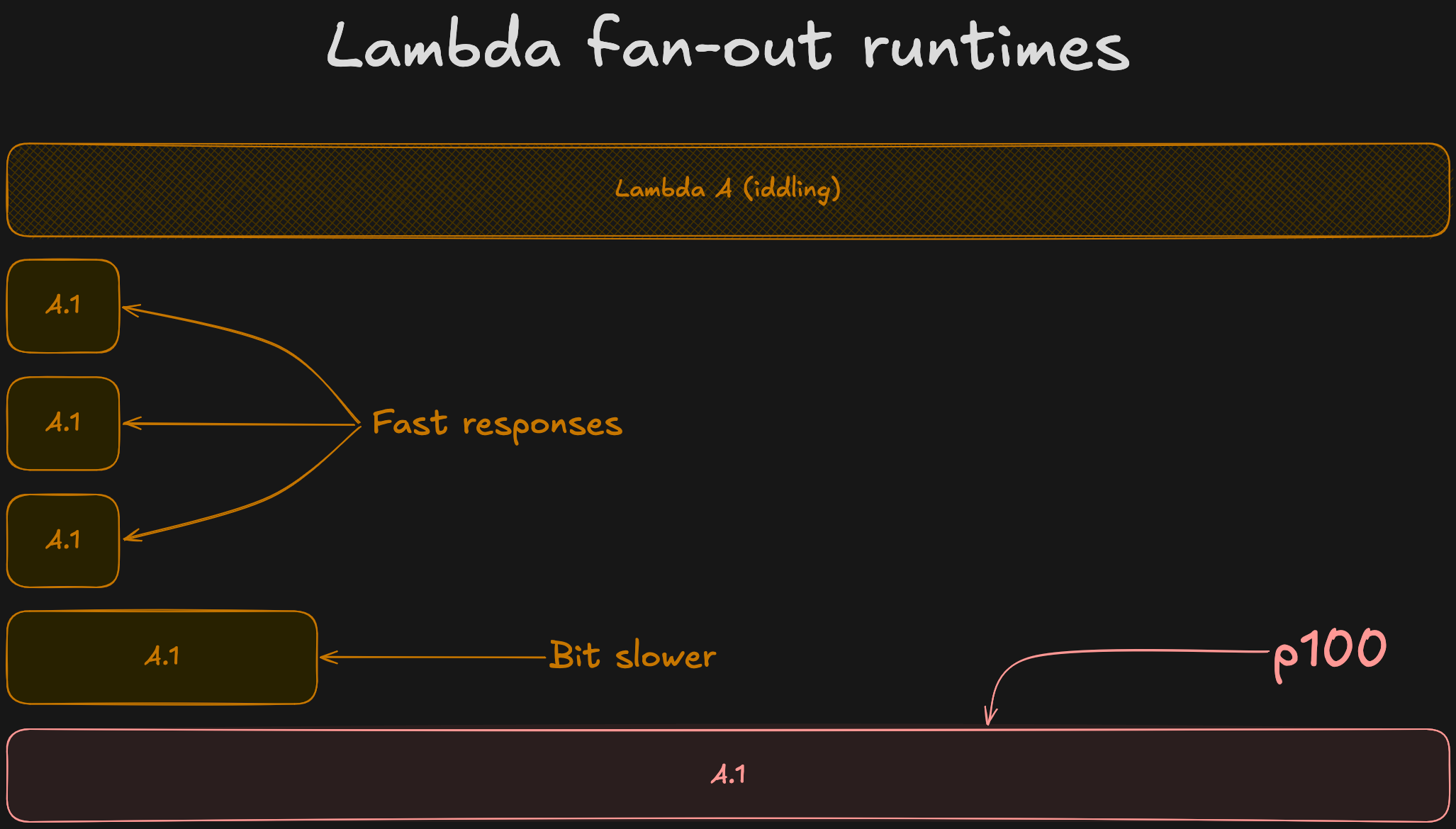
First, the parent Lambda idles until every single child invocation completes. This is the structural equivalent of grabbing a wad of cash and setting it on fire.
Second, your entire response time is hostage to the child Lambda’s p100. In an event-driven architecture, you can progress sequentially as individual chunks complete. With a synchronous implementation, Step B cannot start until the absolute entirety of Step A finishes, Step C is dependent on the p100 of Step B, and so on.
In systems design, this behaviour is known as the straggler problem. We can visualise it as such:
So, why?
While I wasn’t there for its inception, it is easy to understand the original engineering decisions.
The entire codebase was built in Python to run heavily CPU-bound tasks. Because of Python’s single-threaded nature, the team relied on architectural task-splitting (the Lambda fan-out) rather than in-process parallelism.
The rest comes down to velocity: the fastest way to build a new system is the way you already know. Why Python? Because the team knew it. Why a synchronous fan-out? Because it was operationally straightforward to reason about and easy to scale incrementally under delivery pressure.
When you are facing tight deadlines and intense stakeholder pressure, optimise-for-speed decisions make sense. You can always debate language and architecture choices, but ultimately this system has been operational for over half a decade now.
Optimising without rearchitecting
The entire optimisation effort was triggered by customer pain from transient timeouts. Because we needed immediate relief, a massive, high-risk architecture refactor was off the table. Our sole intention was to find tactical wins that would pull our worst-case tail latency safely under the 180-second SLA.
By targeting the hot paths, we managed to achieve a rock-solid, stable execution ceiling while simultaneously shaving 70% off our daily Lambda spend.
To understand how, you have to look at the math of our synchronous fan-out pattern. When you rely on synchronous layers, your end-to-end performance is entirely held hostage by your lowest, slowest leaf node. If a Lambda three levels deep chokes, it drags the entire parent infrastructure down with it.
At our scale, - 1 million daily top level Lambda invocations - getting dragged down by the Lambda 3 levels deep isn’t just a possibility, it’s a mathematical guarantee when your invocation ceiling is 640B invocations/day.
Targeting the multiplier effect
Because an outlier at deeply nested Lambdas is mathematically guaranteed to drag the entire system down, our primary target was flattening the tail latency (p100).
First, we employed simple profiling techniques to identify the hot execution paths. Then came our silver bullet: asking an AI agent to analyse those hot paths specifically and calculate their time complexity. This process flagged multiple algorithms that were ripe for optimisation, falling into two primary categories:
Replacing linear searches for constant-time lookups (O(n) → O(1)): In a single instance, replacing an iterative array loop with a direct hash map for data lookup produced a staggering 44x speedup.
Calculating shared data for parallel tasks once instead of re-doing it (O(N x C) → O(C)): Instead of forcing parallel workers to calculate overlapping elements in isolation, we cached the shared computations upfront. In this case, N refers to the number of elements in the underlying shared dataset, and C refers to the number of parallelised tasks.
Flipping the Statistical Game
The crucial takeaway here wasn’t just the sheer runtime gains made to specific snippets of code. The real victory was securing a guaranteed faster p100 by fundamentally altering our algorithmic time complexity.
For example, flattening a hot path from O(n) to O(1) means that specific chunk of logic is no longer sensitive to scaling. Whether it processes 10 items or 10,000, it takes the exact same fraction of a second.
By removing these variable multipliers from our deeply nested layers, we engineered a hard performance ceiling into our execution tree. We stripped the leaf nodes of their ability to scale out of control, ensuring that a catastrophically slow tail-end outlier can never drag down the runtime of the overall calculation again.
The welcomed side-effect - cost savings
Although cost reduction wasn’t our primary goal, flattening the leaf-node tail latencies had a massive impact on our infrastructure bill.
Once deployed, we observed a 70% decrease in our daily Lambda billed duration. For a system that was costing us over $3k/day/environment in Lambda compute alone, the savings scale to approximately $835k/year/environment.
But how?
AWS Lambda bills on a GB-second model (allocated memory x execution duration). Because of our synchronous fan-out pattern, a tiny runtime optimisation made several layers deep might only shave a few seconds off the end-to-end API response time, but it multiplies exponentially in aggregate.
By optimizing the hot paths, our API’s p99.9 runtime dropped by a modest 20 seconds (from 180s down to 160s to beat the SLA). But under the hood, shrinking those microscopic leaf-node durations eliminated ~9,600 hours of billable Lambda compute time every single day per environment.