
Cost Modelling as an Architectural Constraint: An S3 Case Study
A trillion-object storage architecture that scaled functionally, and nearly triggered a $7.2M lifecycle event.

AWS S3 is widely viewed as inexpensive, effectively unbounded object storage. At moderate scale, this assumption holds. At extreme object cardinality, it fails.
This article analyses a production system that accumulated 5.6 PB of data across 1.56 trillion objects in a single bucket. Within one year, monthly storage cost increased from approximately $100k to over $400k, with forecasts exceeding $1M per month. The root cause was not data volume alone, but architectural fragmentation misaligned with S3’s pricing model.
By consolidating objects to align with S3’s economic structure, equivalent logical data could have been stored at up to 37× lower monthly cost. This case demonstrates that cost modelling must be treated as an architectural constraint.
A More Accurate AWS S3 Cost Model Representation
Object storage is frequently approximated as purely volumetric:
Where:
C = monthly cost
V = stored volume
This mental model is incomplete. A more accurate representation of S3 pricing is:
Where:
C = Total monthly S3 cost
V = Total stored volume (GB)
Pgb = Price per GB-month of storage
Nreq = Total request count (PUT / GET / LIST)
Preq = Price per request
sˉ = Average object size (GB)
P1000 = Price per 1,000 object-level operations (e.g., lifecycle transitions)
At small scale, object count is negligible relative to volume but at larger scales, it becomes a first-order variable. The structural quantity that determines whether object count matters is average object size:
Where:
N = total object count
Inversely, we can express object count in terms of total volume and average object size:
This allows us to restate the object-driven components of the cost model directly in terms of architectural granularity. For a fixed total volume, reducing average object size necessarily increases object count — and therefore amplifies any per-object pricing terms.
We can now use the following cost equation to calculate total cost explicitly as a function of average object size:
This formulation makes object granularity a first-class variable in the cost model. Rather than treating object count as an opaque operational metric, it becomes a direct consequence of architectural design.
When sˉ falls into the kilobyte regime, per-object pricing dominates. The system no longer behaves like bulk storage, instead it’s more akin to a massively distributed index - except you are paying storage-layer economics for index-layer behavior.
A Real-World Example
In the system analyzed:
5.6 PB stored
1.56 trillion objects
~3.5 KB average object size
$400k/month storage cost
~$50k/month in request charges
The architecture generated hundreds of small snapshot artifacts per back end request. Over time, fragmentation compounded. Object count grew faster than volume.
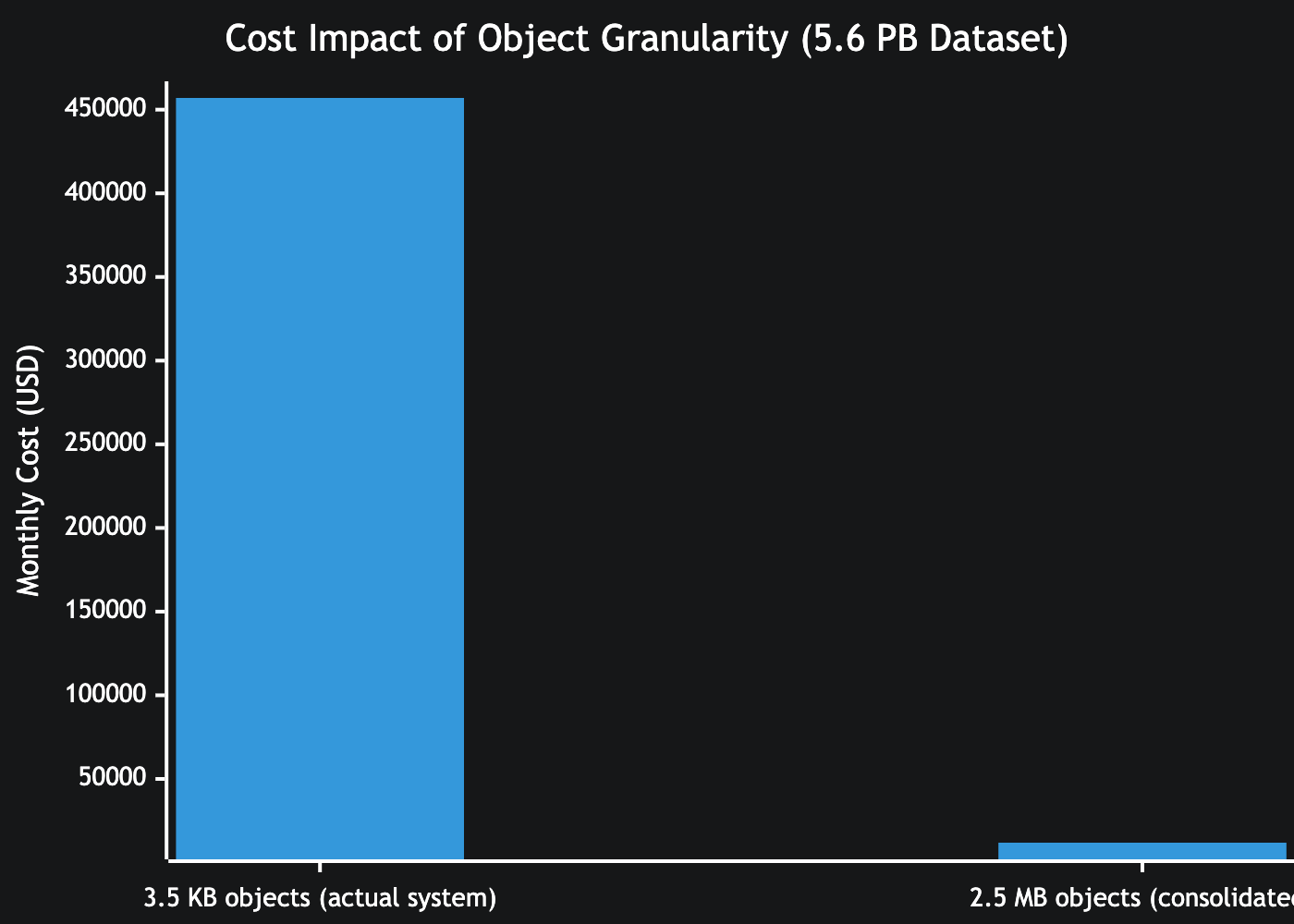
An empirical consolidation experiment showed that equivalent logical data could be stored in artifacts averaging ~2.5 MB.
This would have reduced storage cost from $457,000 to $11,900 per month for the same volume of data. This represents a 37× structural reduction.
This reduction was not due to compression or deletion of data. The total logical volume remained constant. Only object granularity changed.
The $7M Lifecycle Event
Another (nearly) expensive lesson came from trying to fix our exponentially increasing storage costs. Without permanently losing important insights into our service, the only cost saving alternative we believed to have was resorting to lifecycle transition policies.
This solution could have had a seven figure cost, as lifecycle transitions are priced per 1,000 objects. At one point, a single bucket contained approximately 720 billion objects. Meaning:
Approximately $7.2 million — for a single lifecycle rule on a single bucket.
This excludes ongoing storage cost and retrieval penalties.
The transition did not execute because most objects were smaller than 128 KB, which do not transition by default.
Ironically, the same fragmentation pattern that caused excessive steady-state cost also prevented an even larger transition bill.
A Cost Calculation Framework
To prevent similar failures, object storage systems should be evaluated across three explicit budgets.
1. Volume Budget
Projected monthly storage cost.
2. Cardinality Budget
Total object count and average object size.
If average object size falls below a defined threshold (e.g. 1–10 MB for snapshot systems), object count becomes a risk indicator.
3. Remediation Budget
Cost of rewriting, transitioning, or migrating all objects.
Before implementing lifecycle rules or structural migrations, compute:
If remediation cost exceeds acceptable monthly spend, the architecture is already broken.
Object count must be monitored alongside stored bytes. Divergence between the two is architectural drift, not growth.
Conclusion
Our system scaled flawlessly. It simply became unaffordable, under:
Multi-petabyte scale
Trillion-object cardinality
Monthly cost growth from $100k to $400k
Forecast exceeding $1M/month
A potential $7M lifecycle event
Object storage is not purely volumetric. It is priced across bytes, objects, and operations.
At extreme scale, pricing semantics become architectural constraints.
Cost modelling must be treated as a first-class design discipline.
Disclaimer: Based on public AWS pricing and production experience. Not an official AWS statement.